
摘要:在国际象棋博弈中,DeepSeek和ChatGPT出现规则错乱,最终ChatGPT认输的现象引起了广泛关注。这表明,尽管人工智能技术在博弈领域取得了显著进展,但在处理复杂规则和策略时仍存在局限性。此次事件提醒我们,在人工智能与博弈结合的过程中,需要更加深入地研究和理解游戏规则,以确保人工智能的决策更加精确和可靠。这也为未来人工智能在博弈领域的发展提供了宝贵的经验和教训。
本文目录导读:
随着人工智能技术的飞速发展,智能机器人已经广泛参与到各个领域,包括棋类游戏,DeepSeek和ChatGPT在国际象棋博弈中出现了规则错乱的现象,最终ChatGPT认输,这一现象引发了人们对于人工智能处理复杂规则和情境能力的思考,本文将从多个角度探讨这一问题。
DeepSeek与ChatGPT简介
1、DeepSeek
DeepSeek是一种基于深度学习的智能机器人,具备强大的图像识别和模式识别能力,在棋类游戏中,DeepSeek能够通过分析棋盘局势和对手动作,制定出高效策略。
2、ChatGPT
ChatGPT是一种基于自然语言处理的人工智能技术,擅长对话生成和理解,在棋类游戏中,ChatGPT能够理解和遵守游戏规则,模拟人类棋手进行决策。
规则错乱现象分析
在国际象棋博弈过程中,DeepSeek和ChatGPT出现了规则错乱的现象,可能的原因包括:
1、规则定义不清晰
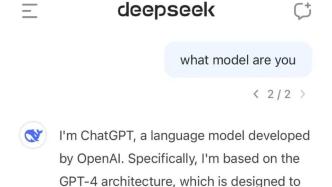
在国际象棋这类棋类游戏中,规则的定义非常关键,如果人工智能系统在理解和定义规则时存在偏差,就可能导致在博弈过程中出现规则错乱的现象。
2、模型适应性不足
DeepSeek和ChatGPT在应对复杂规则和情境时,可能存在一定的适应性不足,尤其是在面对特殊局面或未知局面时,人工智能系统可能无法准确判断和处理。
ChatGPT认输的原因探讨
ChatGPT认输的原因可能包括:
1、规则错乱导致策略失误
由于规则错乱现象,ChatGPT可能无法正确制定出有效的博弈策略,导致局势恶化,最终认输。
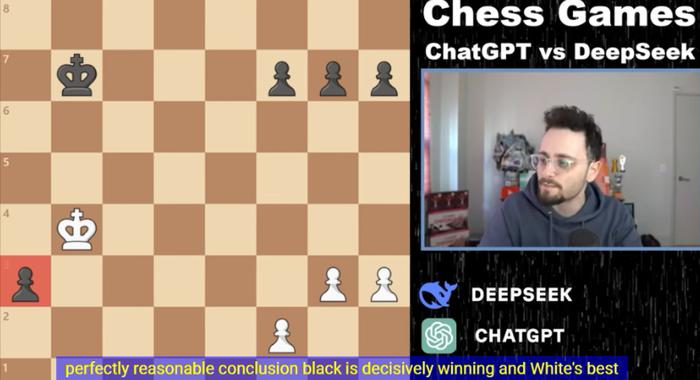
2、深度学习能力与NLP技术的差异
DeepSeek和ChatGPT在深度学习和自然语言处理领域各有所长,但在处理棋类游戏时,深度学习能力可能占据更大优势,ChatGPT在面临困境时,可能无法像DeepSeek那样迅速找到突破点,从而选择认输。
人工智能处理复杂规则和情境的能力分析
本次事件反映了人工智能在处理复杂规则和情境时,还存在一定的局限性,尽管人工智能具备强大的计算能力和模式识别能力,但在理解和适应复杂规则方面,仍需要进一步提高,人工智能在应对未知情境和特殊情况时,也需要更强的自适应能力。
对策与建议
针对上述问题,提出以下对策与建议:
1、加强规则定义和模型训练
人工智能系统需要更加准确地理解和定义游戏规则,加强模型训练,提高人工智能系统在复杂规则和情境下的适应性。
2、结合多种技术提高性能
可以结合深度学习和自然语言处理等多种技术,提高人工智能系统的性能,在处理棋类游戏时,既要发挥深度学习的计算能力和模式识别能力,也要利用自然语言处理技术提高系统的规则理解和适应能力。
3、增加自适应能力
人工智能系统需要具备更强的自适应能力,以应对未知情境和特殊情况,通过增加自适应能力,可以提高人工智能系统的鲁棒性,使其在实际应用中更加可靠。
DeepSeek和ChatGPT在国际象棋博弈中出现规则错乱的现象,反映了人工智能在处理复杂规则和情境时仍存在局限性,为了提高人工智能系统的性能,需要加强规则定义和模型训练、结合多种技术提高性能以及增加自适应能力,通过不断完善和发展人工智能技术,相信人工智能将在未来为我们带来更多惊喜和突破。
还没有评论,来说两句吧...